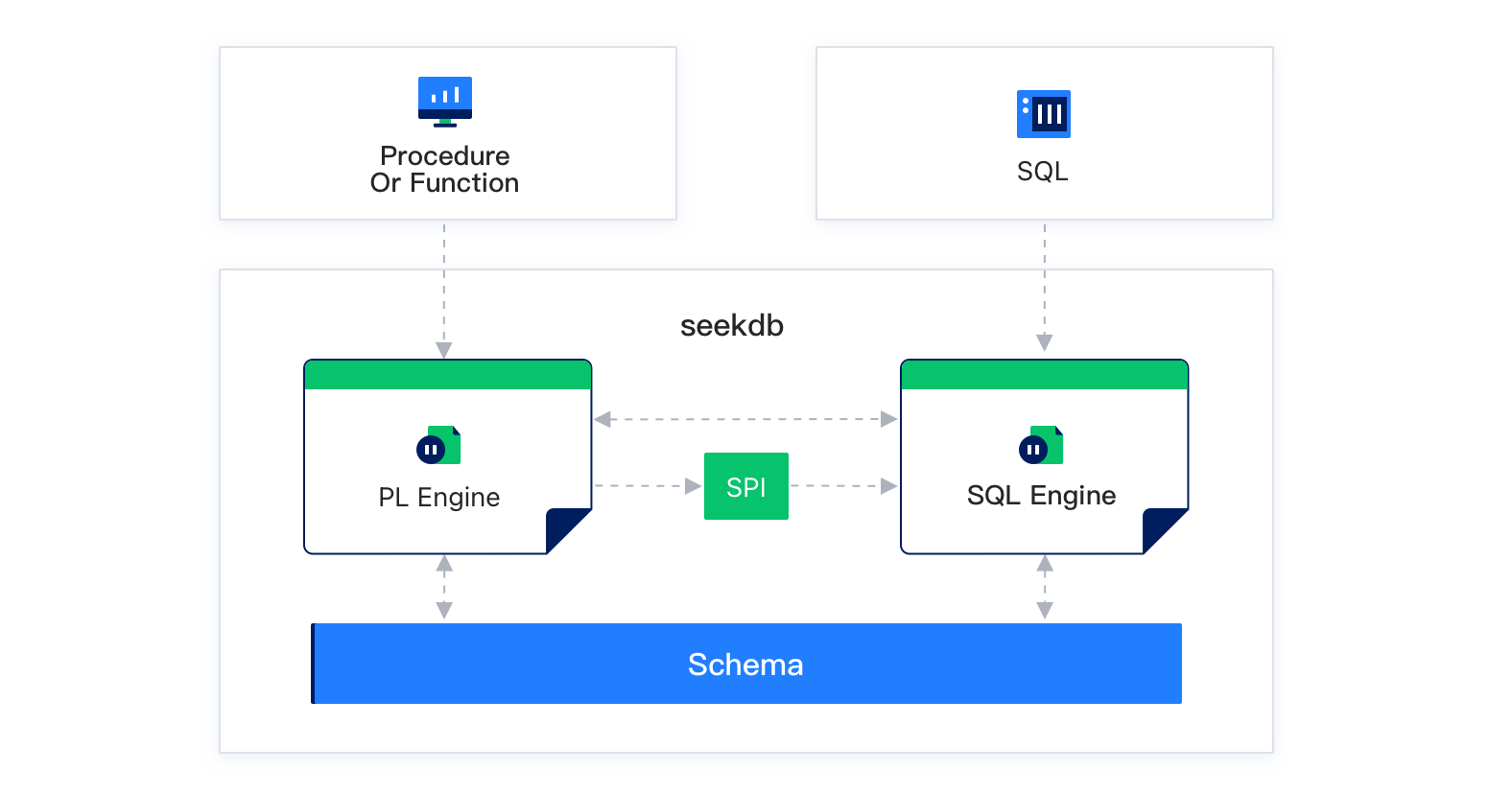
PL 的架构
PL 引擎(PL Engine)和 SQL 引擎(SQL Engine)可以交互工作。SQL 可以直接访问 PL 引擎,�例如 SQL 语句可以使用用户自定义函数。PL 可以通过 SPI 接口访问 SQL 引擎,进行表达式计算和执行 SQL 语句。
两者的交互关系如下图所示:
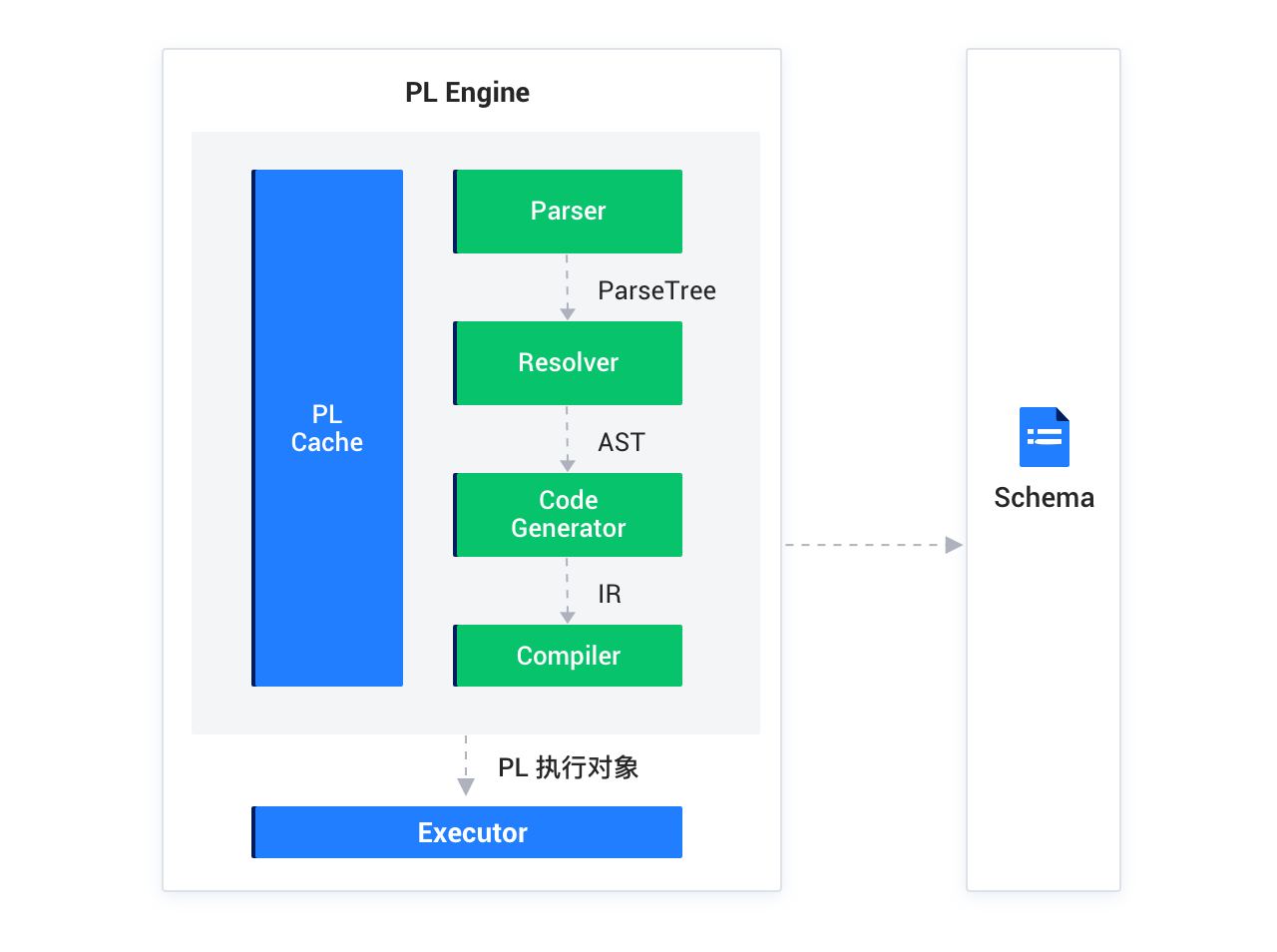
PL Engine 由六个模块组成,分别是 Parser、Resolver、Code Generator、Compiler、Executor 和 PL Cache,其中 Parser、Resolver、Code Generator 和 Compiler 构成了一个完整的 PL 编译流程。如下图所示:
-
Parser(语法解析器)
Parser 用于分析 PL 语法并生成语法树(Parse Tree)。PL 引擎和 SQL 引擎各自实现了单独的 Parser,但是两个 Parser 尽量不做冗余的工作。在 seekdb 中,一个查询串首先进入 PL Parser 进行解析,如果发现是 SQL 语句则交由 SQL 引擎进行解析。
-
Resolver(语义解析器)
Resolver 用于进行语义分析,例如检查变量作用域、静态 SQL 中数据对象的 Schema 等,并为每一条 PL 语句生成对应的抽象语法树 AST 结构以及全局的 AST 结构。AST 存储了 PL 定义的基本信息和生成的全局符号表、全局标签表、全局异常表等信息。每一条语句的 AST 里面则记录了指向这些全局表的逻辑信息。
-
Code Generator(代码生成器)
Code Generator 使用 LLVM 提供的接口对 AST 进行进一步的翻译,把 AST 树翻译成 IR 中间码。IR 码可以用来核对检验翻译过程是否正确。
-
Compiler(编译器)
Compiler 通过即时编译 JIT 把 IR 码生成机器码,输出为可执�行的 PL 对象。
-
Executor(执行器)
Executor 根据编译出的 PL 可执行对象和输入参数构造执行环境,并调用函数指针,得到函数结果。
-
PL Cache(执行计划缓存模块)
PL Cache 是 PL Engine 的内部机制,PL Engine 对外提供统一的通过 ID 执行 Procedure 或 Function 的接口,外部不必了解 PL 的缓存机制,只需通过 PL Engine 执行 PL 即可。PL Cache 是一个 Hash 表,通过 Key(Procedure 或 Function 的 ID)查找到 Value(PL 执行对象),并通过访问 Schema 检查 PL 可执行对象的有效性,如果失效则立即删除。PL Cache 用于避免每一次都重新编译 PL,可以提升 PL 的执行效率,所以对于匿名块(Anonymous Block)就没有使用 Cache 的必要。
PL Engine 对外提供 Execute 接口,其参数包括 PL ID、执行参数 params、执行环境 Context 和执行结果 Result(仅对 Function 有效)。首先根据 ID 在 PL Cache 查找是否有编译好的 PL 可执行对象,如果有则进一步检查 Version 是否可用。如果 PL Cache 中没有可用的 PL 可执行对象,则调用编译流程进行编译,编译后的结果缓存在 PL Cache 中,并交给 Executor 执行。编译的结果是一段二进制代码的内存地址,Executor 将这段内存地址转成一个函数指针,并传入执行参数和执行环境运行得到结果。