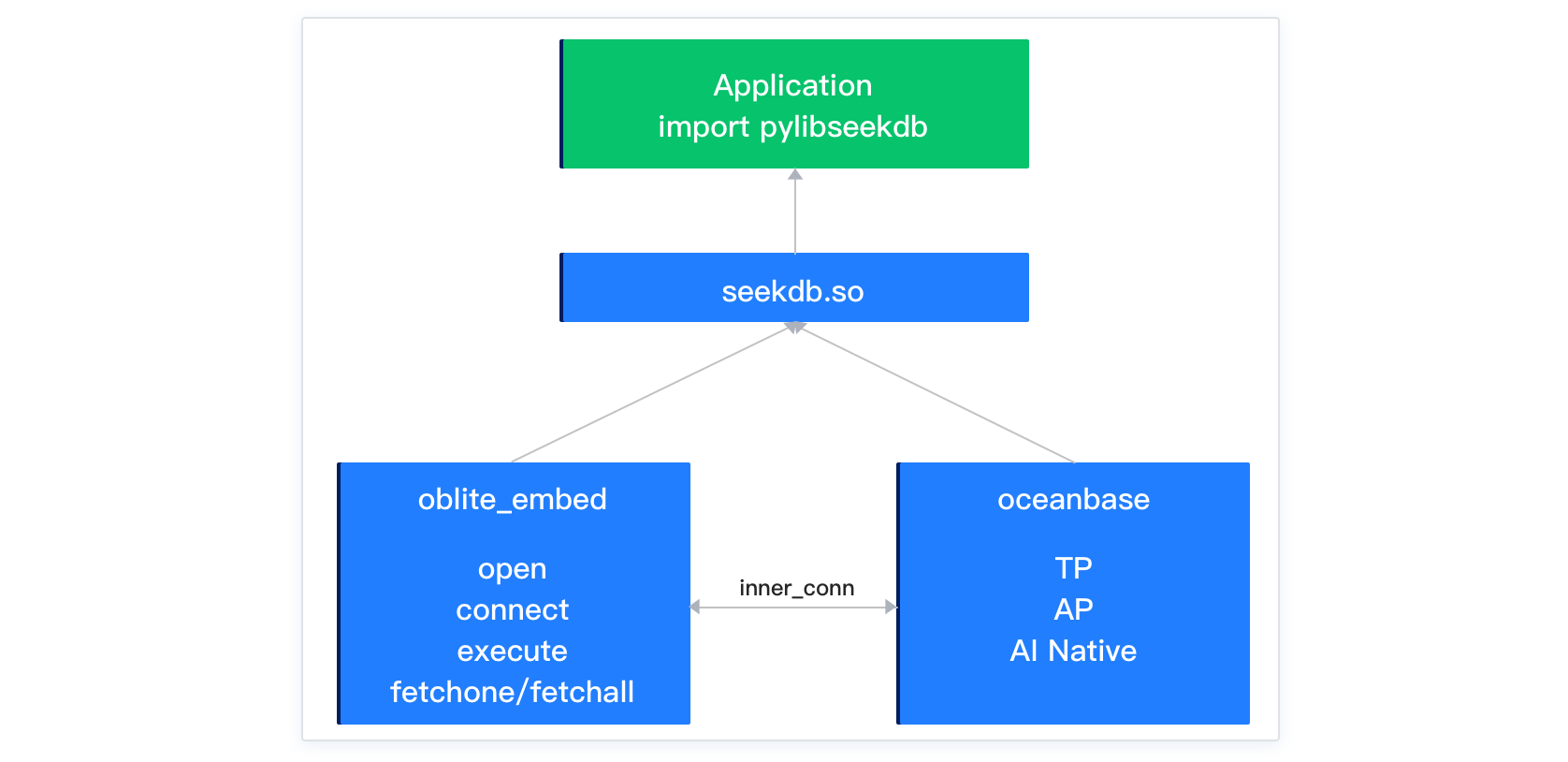
Experience embedded seekdb
seekdb provides an embedded product form that can be integrated into user applications as a library, offering developers a more powerful and flexible data management solution. This enables data management everywhere (microcontrollers, IoT devices, edge computing, mobile applications, data centers, etc.), allowing users to quickly get started with seekdb's All-in-one (TP, AP, AI Native) capabilities.
Installation and configuration
Environment requirements
-
Supported operating systems: Linux (glibc >= 2.28)
-
Supported Python versions: CPython 3.8 ~ 3.14
-
Supported system architectures: x86_64, aarch64
You can run the following command to check whether your environment meets the requirements.
python -c 'import sys;import platform; print(f"Python: {platform.python_implementation()} {platform.python_version()}, System: {platform.system()} {platform.machine()}, {platform.libc_ver()[0]}: {platform.libc_ver()[1]}");'
The output should be like this:
Python: CPython 3.8.17, System: Linux x86_64, glibc: 2.32
Installation
Use pip to install. It automatically detects the default Python version and platform.
pip install pylibseekdb
# Or specify a mirror source for faster installation
pip install pylibseekdb -i https://pypi.tuna.tsinghua.edu.cn/simple
If your pip version is low, upgrade pip first before installation:
pip install --upgrade pip
Experience seekdb
After completing the installation of seekdb, you can start experiencing seekdb.
Experience basic seekdb operations
The following examples demonstrate some basic operations of seekdb. You can create databases, connect to databases, create tables, write and query data, and more.
For detailed information about seekdb SQL syntax, see SQL syntax.
seekdb provides the test database by default. The following example demonstrates how to open and connect to the test database using default parameters, and how to create tables, write data, commit transactions, query data, and safely close the database.
import pylibseekdb
# Open the database directory seekdb by default
pylibseekdb.open()
# Connect to the test database by default
conn = pylibseekdb.connect()
# Create a cursor for data operations
cursor = conn.cursor()
# Execute table creation statement
cursor.execute("create table t1(c1 int primary key, c2 int)")
# Execute data insertion
cursor.execute("insert into t1 values(1, 100)")
cursor.execute("insert into t1 values(2, 200)")
# Manually commit the transaction
conn.commit()
# Execute query
cursor.execute("select * from t1")
# Fetch results
print(cursor.fetchall())
# Close connections
cursor.close()
conn.close()
You can also manually specify the database directory and create and use a new database.
import pylibseekdb
# Specify the database directory
pylibseekdb.open("mydb")
# Do not connect to any database
conn = pylibseekdb.connect("")
# Create a cursor for data operations
cursor = conn.cursor()
# Manually create a database
cursor.execute("create database db1")
# Use the newly created database
cursor.execute("use database db1")
# Close connections
cursor.close()
conn.close()
The following example demonstrates how to enable autocommit mode for transactions.
import pylibseekdb
# Specify the database directory
pylibseekdb.open("seekdb")
# Connect to the test database
conn = pylibseekdb.connect(database="test", autocommit=True)
# Create a cursor for data operations
cursor = conn.cursor()
# Execute table creation statement
cursor.execute("create table t1(c1 int primary key, c2 int)")
# Execute data insertion, transaction is automatically committed
cursor.execute("insert into t1 values(1, 100)")
# Execute data insertion, transaction is automatically committed
cursor.execute("insert into t1 values(2, 200)")
# Query data using a new connection
conn2 = pylibseekdb.connect("test")
cursor2=conn2.cursor()
cursor2.execute("select * from t1")
# View data row by row
print(cursor2.fetchone())
print(cursor2.fetchone())
# Close connections
cursor.close()
conn.close()
cursor2.close()
conn2.close()
Experience seekdb
Experience AI Native
Experience vector search
seekdb supports up to 16,000 dimensions of float-type dense vectors, sparse vectors, and various types of vector distance calculations such as Manhattan distance, Euclidean distance, inner product, and cosine distance. It supports creating vector indexes based on HNSW/IVF, and supports incremental updates and deletions without affecting recall.
For more detailed information about seekdb vector search, see Vector search.
The following example demonstrates how to use vector search in seekdb.
import pylibseekdb
pylibseekdb.open("seekdb")
conn = pylibseekdb.connect("test")
cursor = conn.cursor()
# Create a table with a vector index
cursor.execute("create table test_vector(c1 int primary key, c2 vector(2), vector index idx1(c2) with (distance=l2, type=hnsw, lib=vsag))")
# Insert data
cursor.execute("insert into test_vector values(1, [1, 1])")
cursor.execute("insert into test_vector values(2, [1, 2])")
cursor.execute("insert into test_vector values(3, [1, 3])")
conn.commit()
# Execute vector search
cursor.execute("SELECT c1,c2 FROM test_vector ORDER BY l2_distance(c2, '[1, 2.5]') APPROXIMATE LIMIT 2;")
# Fetch results
print(cursor.fetchall())
# Close connections
cursor.close()
conn.close()
Experience full-text search
seekdb provides full-text indexing capabilities. By building full-text indexes, you can comprehensively index entire documents or large text content, significantly improving query performance when dealing with large-scale text data and complex search requirements, enabling users to obtain the required information more efficiently.
The following example demonstrates how to use seekdb's full-text search feature.
import pylibseekdb
pylibseekdb.open("seekdb")
conn = pylibseekdb.connect("test")
cursor = conn.cursor()
# Create a table with a full-text index
sql='''create table articles (title VARCHAR(200) primary key, body Text,
FULLTEXT fts_idx(title, body));
'''
cursor.execute(sql)
# Insert data
sql='''insert into articles(title, body) values
('OceanBase Tutorial', 'This is a tutorial about OceanBase Fulltext.'),
('Fulltext Index', 'Fulltext index can be very useful.'),
('OceanBase Test Case', 'Writing test cases helps ensure quality.')
'''
cursor.execute(sql)
conn.commit()
# Execute full-text search
sql='''select
title,
match (title, body) against ("OceanBase") as score
from
articles
where
match (title, body) against ("OceanBase")
order by
score desc
'''
cursor.execute(sql)
# Fetch results
print(cursor.fetchall())
# Close connections
cursor.close()
conn.close()
Experience hybrid search
Hybrid Search combines vector-based semantic search and full-text index-based keyword search, providing more accurate and comprehensive search results through comprehensive ranking. Vector search excels at semantic approximate matching but is weak at matching exact keywords, numbers, and proper nouns, while full-text search effectively compensates for this deficiency. Therefore, hybrid search has become one of the key features of vector databases and is widely used in various products.
Based on multi-model integration, seekdb provides hybrid search capabilities for multi-modal data on the basis of SQL+AI, enabling fusion queries of multiple types of data in a single database system.
The following example demonstrates how to use seekdb's hybrid search feature.
import pylibseekdb
pylibseekdb.open("seekdb")
conn = pylibseekdb.connect("test")
cursor = conn.cursor()
# Create a table with vector indexes and full-text indexes
cursor.execute("create table doc_table(c1 int, vector vector(3), query varchar(255), content varchar(255), vector index idx1(vector) with (distance=l2, type=hnsw, lib=vsag), fulltext idx2(query), fulltext idx3(content))")
# Insert data
sql = '''insert into doc_table values(1, '[1,2,3]', "hello world", "oceanbase Elasticsearch database"),
(2, '[1,2,1]', "hello world, what is your name", "oceanbase mysql database"),
(3, '[1,1,1]', "hello world, how are you", "oceanbase oracle database"),
(4, '[1,3,1]', "real world, where are you from", "postgres oracle database"),
(5, '[1,3,2]', "real world, how old are you", "redis oracle database"),
(6, '[2,1,1]', "hello world, where are you from", "starrocks oceanbase database");'''
cursor.execute(sql)
conn.commit()
sql = '''set @parm = '{
"query": {
"bool": {
"must": [
{"match": {"query": "hi hello"}},
{"match": { "content": "oceanbase mysql" }}
]
}
},
"knn" : {
"field": "vector",
"k": 5,
"num_candidates": 10,
"query_vector": [1,2,3],
"boost": 0.7
},
"_source" : ["query", "content", "_keyword_score", "_semantic_score"]
}';'''
cursor.execute(sql)
# Execute hybrid search
sql = '''select dbms_hybrid_search.search('doc_table', @parm);'''
cursor.execute(sql)
# Fetch results
print(cursor.fetchall())
# Close connections
cursor.close()
conn.close()
Experience analytical capabilities (OLAP)
seekdb combines transaction processing (TP) with analytical processing (AP). Based on the LSM-Tree architecture, it achieves unified row and column storage, and introduces a new vectorized engine and cost evaluation model based on column storage, significantly improving the efficiency of processing wide tables and enhancing query performance in AP scenarios. It also supports real-time import, secondary indexes, high-concurrency primary key queries, and other common real-time OLAP requirements.
Experience data import
seekdb supports various flexible data import methods, allowing you to import data from multiple data sources into the database. Different import methods are suitable for different scenarios. You can choose appropriate import tools for data import based on data source types and business scenarios. As scenarios become more complex and diverse, multiple import methods can be used together. When importing data, in addition to considering data sources, data file formats should also be considered along with the support of import tools. When business scenarios have clearly defined data sources and data file formats, you need to start from the data source and consider the design of the import solution in combination with import tools. When businesses have import tools they are familiar with, you need to consider the tool's support and the possibility of import in combination with business scenarios.
The following example uses the load data method to demonstrate how to quickly import CSV data into seekdb.
-
Create an external data source
cat /data/1/example.csv
1,10
2,20
3,30 -
Import external data using the embedded method.
import pylibseekdb
pylibseekdb.open("seekdb")
conn = pylibseekdb.connect("test")
cursor = conn.cursor()
# Create a table
cursor.execute("create table test_olap(c1 int, c2 int)")
# Execute fast import
cursor.execute("load data /*+ direct(true, 0) */ infile '/data/1/example.csv' into table test_olap fields terminated by ','")
# Query data
cursor.execute("select count(*) from test_olap")
# Fetch results
print(cursor.fetchall())
# Close connections
cursor.close()
conn.close()
Experience columnar storage
In scenarios involving complex analysis of large-scale data or ad-hoc queries on massive data, columnar storage is one of the key capabilities of AP databases. The seekdb storage engine has been further enhanced on the basis of supporting row storage, achieving support for column storage and unified storage. With one codebase, one architecture, and one instance, columnar data and row data coexist.
The following example demonstrates how to create a columnar table in seekdb.
import pylibseekdb
pylibseekdb.open("seekdb")
conn = pylibseekdb.connect("test")
cursor = conn.cursor()
# Create a columnar table
sql='''create table each_column_group (col1 varchar(30) not null, col2 varchar(30) not null, col3 varchar(30) not null, col4 varchar(30) not null, col5 int)
with column group (each column);
'''
cursor.execute(sql)
# Insert data
sql='''insert into each_column_group values('a', 'b', 'c', 'd', 1)
'''
cursor.execute(sql)
conn.commit()
# Execute query
cursor.execute("select col1,col2 from each_column_group")
# Fetch results
print(cursor.fetchall())
# Close connections
cursor.close()
conn.close()
Experience materialized views
Materialized views are a key feature supporting AP business. They improve query performance and simplify complex query logic by precomputing and storing query results of views, reducing real-time computation. They are commonly used in fast report generation and data analysis scenarios. seekdb supports non-real-time and real-time materialized views, supports specifying primary keys or creating indexes for materialized views, and introduces nested materialized views, which can significantly improve query performance.
The following example demonstrates how to use materialized views in seekdb.
import pylibseekdb
import time
pylibseekdb.open("seekdb")
conn = pylibseekdb.connect("test")
cursor = conn.cursor()
# Create base tables
cursor.execute("create table base_t1(a int primary key, b int)")
cursor.execute("create table base_t2(c int primary key, d int)")
# Create materialized view logs
cursor.execute("create materialized view log on base_t1 with(b)")
cursor.execute("create materialized view log on base_t2 with(d)")
# Create a materialized view named mv based on tables base_t1 and base_t2, specify the refresh strategy as incremental refresh, and set the initial refresh time in the refresh plan to the current date, then refresh the materialized view every 1 second thereafter.
cursor.execute("create materialized view mv REFRESH fast START WITH sysdate() NEXT sysdate() + INTERVAL 1 second as select a,b,c,d from base_t1 join base_t2 on base_t1.a=base_t2.c")
# Insert data into base tables
cursor.execute("insert into base_t1 values(1, 10)")
cursor.execute("insert into base_t2 values(1, 100)")
conn.commit()
# Wait for the materialized view background refresh to complete
time.sleep(10)
# Query data
cursor.execute("select * from mv")
# Fetch results
print(cursor.fetchall())
# Close connections
cursor.close()
conn.close()
Experience external tables
Typically, table data in a database is stored in the database's storage space, while external table data is stored in external storage services. When creating an external table, you need to define the data file path and data file format. After creation, users can read data from files in external storage services through external tables.
The following example demonstrates how to access external CSV files through seekdb's external table feature.
-
Create an external data source.
cat /data/1/example.csv
1,10
2,20
3,30 -
Access external table data using the embedded method.
import pylibseekdb
pylibseekdb.open("seekdb")
conn = pylibseekdb.connect("test")
cursor = conn.cursor()
# Create an external table
sql='''CREATE EXTERNAL TABLE test_external_table(c1 int, c2 int) LOCATION='/data/1' FORMAT=(TYPE='CSV' FIELD_DELIMITER=',') PATTERN='example.csv';
'''
cursor.execute(sql)
# Query data
cursor.execute("select * from test_external_table")
# Fetch results
print(cursor.fetchall())
# Close connections
cursor.close()
conn.close()
Experience transaction capabilities (OLTP)
The following example demonstrates seekdb's transaction capabilities.
import pylibseekdb
pylibseekdb.open("seekdb")
conn = pylibseekdb.connect("test")
cursor = conn.cursor()
# Create a table
cursor.execute("create table test_oltp(c1 int primary key, c2 int)")
# Insert data
cursor.execute("insert into test_oltp values(1, 10)")
cursor.execute("insert into test_oltp values(2, 20)")
cursor.execute("insert into test_oltp values(3, 30)")
# Commit transaction
conn.commit()
# Query data, ORA_ROWSCN is the data commit version number
cursor.execute("select *,ORA_ROWSCN from test_oltp")
# Fetch results
print(cursor.fetchall())
# Close connections
cursor.close()
conn.close()
Smooth transition to the distributed version
After users quickly validate product prototypes through the embedded version, if they want to switch to seekdb Server mode or use OceanBase's distributed version cluster processing capabilities, they only need to modify the import package and related configuration, while the main application logic remains unchanged.
import pylibseekdb
pylibseekdb.open()
conn = pylibseekdb.connect()
Simply replace the three lines above with the two lines below. Use the pymysql package to replace pylibseekdb, remove the pylibseekdb open phase, and use pymysql's connect method to connect to the database server.
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=11002, user='root@sys', database='test')